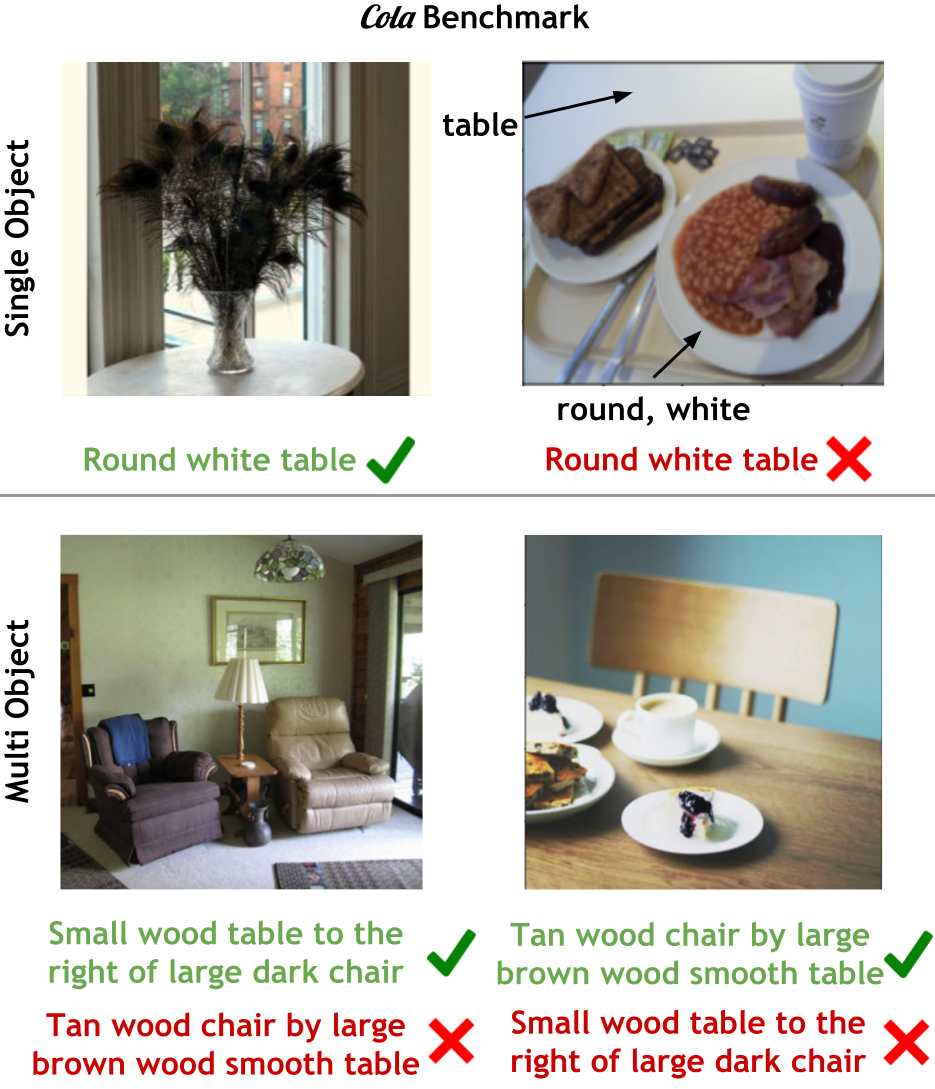
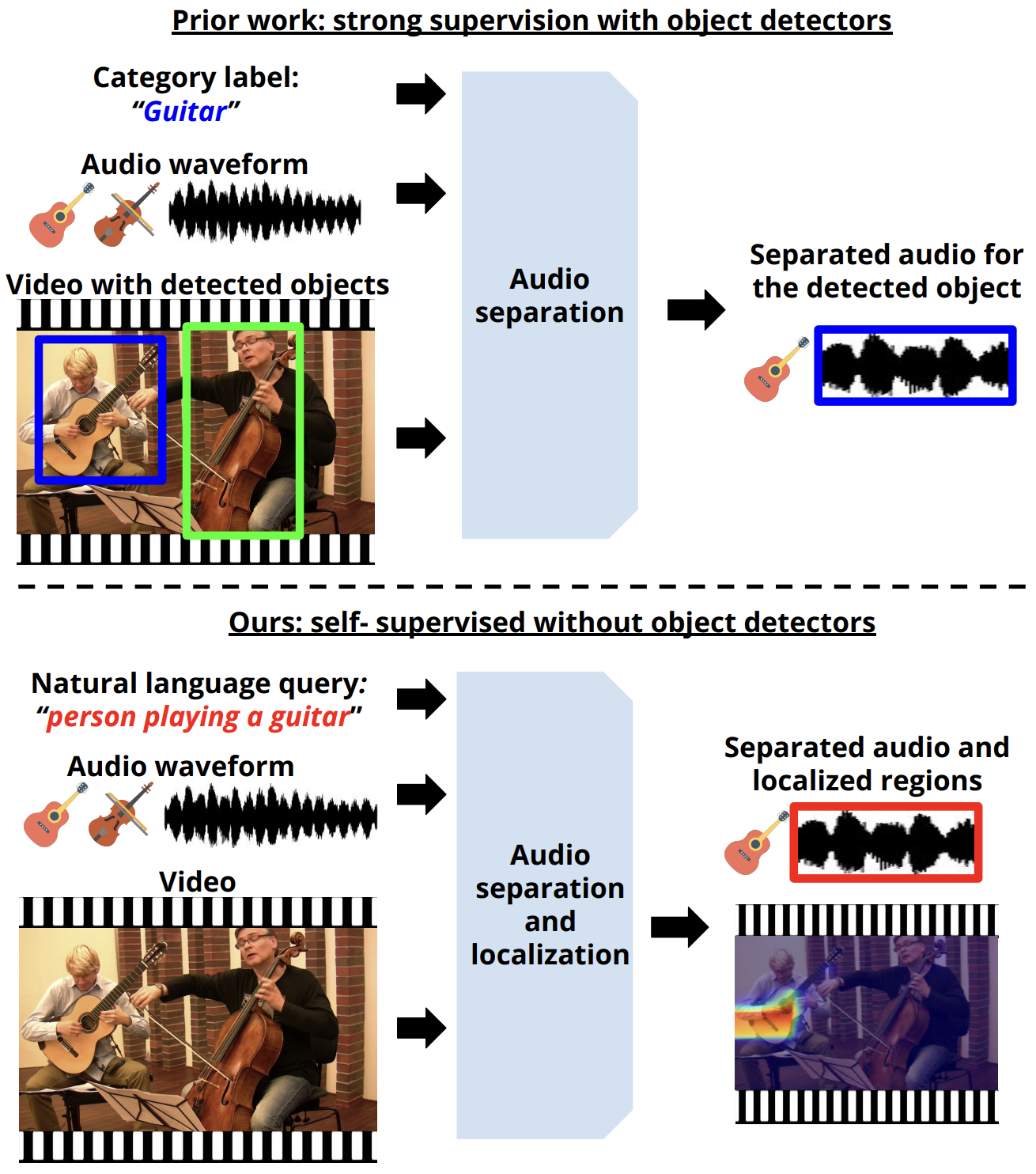
I wish to teach machines to help humans achieve more in the world.
About me and my research:
I am a Computer Vision Ph.D. Student at Boston University (BU), advised by Kate Saenko and Bryan Plummer. I collaborate closely with Ranjay Krishna from the University of Washington and am a student collaborator in the PRIOR Team at Allen AI. I received my M.S from Virginia Tech, advised by Devi Parikh.
Recently, I am interested in endowing AI models with spatial intelligence to help them effectively take actions in the 3D world. Since obtaining such annotations is expensive, I wish to teach models to imagine scenarios in 3D simulations and learn from them to generalize to the real world. I also enjoy creating ecosystems that encourage creative building. Hence, I am a member of the AI for Impact Venture Studio at MIT.
If you are interested to collaborate or just chat about research on multimodal models to help human creativity, say hi!